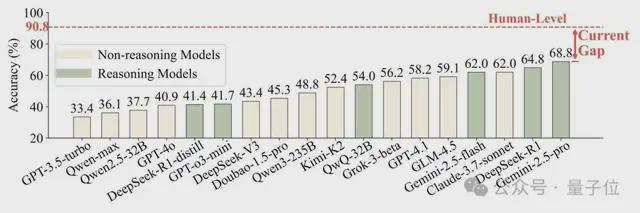
 大语言模型(LLM)已从工具转变为“法官”(LLM-AS-A-A-A-A-Jewish),并开始判断AI在该规模上产生的内容。这种有效的评估范式的可靠性和人类试验的一致性很少经过详细验证。最基本和最重要的问题是,在确定模型是否在“工作中”之前,法官能否精确地确定谁在对话中说话?为了回答这个问题,文件是:“人:LLM的评估者是否足以判断角色玩游戏?” Jorge de Shanghai的Wang Dequan研究团队就此进行了系统的研究。本文提出了一个名为Personaval的新参考点。该测试的核心任务是允许模型从几个候选人的角色中选择真实的扬声器。测试结果表明,即使是最佳的REN ModelGemini-2.5-Pro dimense,它的精度率仅为68.8%,并且人类实验的平均精度率Imental组为90.8%。该文档将于2025年10月在第二语言建模会议(COLM)发表。最近,关于大型语言模型是否能够“试验”,就越来越多地讨论了一个关于主要模型的“出现”的简单问题。从“看不见的配件”影响大规模模型的修订到试图为斯坦福大学纯粹学术会议的第一个代理人做准备的争议,这标志着新趋势的到来。这种趋势在角色扮演领域尤为突出。由于大型模型在各种应用程序中扮演着经典的文学角色和游戏NPC,并在各种应用程序中扮演“ AI Play”的出现,因此虚拟同学和康提创作的时代已经超越了我们。凭借其巨大的商业和应用可能性吸引了对行业的普遍护理,如何评估AI的“ AI技能”自然已成为一个核心问题紧急解决。因此,确保LLM担任法官自然已成为该领域的常规评估方法之一。在本文中AI成为法官之前,我们必须验证AI是否可以精确执行“角色识别”。作者认为,如果他甚至不能这样做,那么对随后的语气,情感和个性一致性的所有高级评估都将在空中。如下图所示,让我们以一个非常简单的示例进行人眼。在她的内部独白中,她清楚地提到了“ lu ji”,并用她的话提到了“老师luo”。 Hum判断力的逻辑:对于那些尚未阅读“三个身体问题”的人,可以告诉Zhuang Yan,由于内部独白和Zhuang Yan的音频内容的交织在一起,他正在与Luo Ji交谈。游戏是最直接,最关键的上下文曲目。换句话说,这是决定的逻辑E参与者参加对话。但是,在这种情况下,顶级LLM(DeepSeek-R1-0528)做出了错误的判断,并选择了什叶派。该模型分析表明,尽管“ Lu ji忽略了对话参与者的中心情境信息”,但要过分关注受访者的语言风格。该示例指出了LLM当前裁判中的致命缺陷。他们似乎更多地专注于肤浅的语言(听力)风格,但人类首先观察到真实的意图和对话的背景(在这种情况下,他们会这么说)。为什么会出现这种分歧?在此背后,IA和人类智力模型之间存在显着差异。正如认知科学家Josh Tenenbaum在他的文章中引用的那样,LLM Intelligence“源自大型语言学习模式”,并且是适合上层模式的专家。人类智能在语言上“进步”,但我们开发和使用有意图的语言工具gnition。 Perseval:专门为LLM裁判设计的“恶魔镜子”已仔细地建立了一个个性参考点,以系统地评估LLM的性格识别技能。一些确保评估与人类一致的中心特征和特定挑战:源自纯人类创造的挑战:所有对话数据均来自小说,真实的人类脚本和视频,而不包含与AI同步的。这样可以确保评估标准植根于人类判断的真实标准,并且“对模型的评估”避免了模型数据的污染。 “设计良好”的干扰器:在多个选择任务中,不正确的选项(干扰器)不是随机建立的,但是“模仿”字符是通过最接近正确角色的集成技术仔细选择的。这将导致模型执行微妙的推理,而不是模式的简单巧合。它专注于“困难而复杂的疾病为了避免在简单案例中避免性能并错误地取消模型,纸张作者通过强大的参考模型(Qwen-max)进行过滤,并且仅维护“硬核案例”,即使在强大的模型中,这些案例也被混淆了(可靠性低于0.5)。 perseval-drama:在与中文脚本的互动中,对模型的理解。 一些主要模型,包括GPT系列,Claude系列和DeepShek系列。结果表明,即使是最佳的Gemini-2.5-Pro性能模型,精度率也仅为68.8%。相反,作者在人类中组织研究,其中包括20名受过良好教育的志愿者,TASA平均人类精度为90.8%! △图3:人类和人类水平的LLM精度的比较。上图直觉上说明了这个巨大的“差距”(当前差距)。这清楚地回答了文档标题中的问题。 LLM目前的裁判远非“拟人化”,足以确保角色玩游戏。完成空白我该怎么做?加强“推论”而不是“喂”角色的知识很重要。由于发现问题,我应该如何解决问题?作者进一步研究了改进模型的两种一般策略:“注入”通过调整自适应中对模型中字符的更多知识n训练时间:角色游戏语料库。测试时间计算:推理阶段通过诸如小指示和自我整合性等方法提高了性能。结果再次出乎意料。这项研究与他相矛盾,与模型相关的精细调整不仅可以提高角色识别能力,还可以导致性能降解。这可能是由于以下事实:记忆性字符的知识使得模型的一般推理能力变得困难。 △图4:使用文本数据(粉红色列)进行调整后,将降低模型性能。同时,被测试的计算方法显示出更大的可能性,尤其是针对“推理”所生的模型。例如,针对推理任务进行了优化的DeepSeek-R1和QWQ-32B之类的模型被分类在参考点的顶部。这表明,如果您想建立一个良好的“ AI裁判”,那么重要的是不要注入更多的了解CTERS,但要使用上下文的强大,强大和有意识的推理引擎来改善模型本身。该文档揭示了E Paradigmvaluation LLM-As-A-Jewish流行和严重失败的严重失败。这项研究不仅提供了有价值的评估工具,而且还鼓励我们重新考虑如何构建与人类价值观和判断真正保持一致的AI系统。未来的研究可能会在模型的“思维方式”中犯错,这些模型可以发展出更有效和以推理为导向的形式。 Perseval正在朝着这一目标迈进。最终,AI确实“理解”人类如何互动,不仅是人类,而且是人类。作者的个人资料本文的第一作者是上海大学的博士生周·林冯(Zhou Lingfeng)。他授权大型模型代理和人工智能。我正在调查社会科学。本文的相应作者是助理教授Wang DequanR和医生的主管在上海豪尔赫大学。他与来自伯克利分校的本科毕业生和博士毕业生的特雷弗·达雷尔(Trevor Darrell)教授学习。在过去的五年中,Google Scholar日期的总数已超过12,000,H-Index 22。项目链接:https://github.com/maple-zhou/personaeval’s地址:https://arxiv.org/abs/2508.1001444
大语言模型(LLM)已从工具转变为“法官”(LLM-AS-A-A-A-A-Jewish),并开始判断AI在该规模上产生的内容。这种有效的评估范式的可靠性和人类试验的一致性很少经过详细验证。最基本和最重要的问题是,在确定模型是否在“工作中”之前,法官能否精确地确定谁在对话中说话?为了回答这个问题,文件是:“人:LLM的评估者是否足以判断角色玩游戏?” Jorge de Shanghai的Wang Dequan研究团队就此进行了系统的研究。本文提出了一个名为Personaval的新参考点。该测试的核心任务是允许模型从几个候选人的角色中选择真实的扬声器。测试结果表明,即使是最佳的REN ModelGemini-2.5-Pro dimense,它的精度率仅为68.8%,并且人类实验的平均精度率Imental组为90.8%。该文档将于2025年10月在第二语言建模会议(COLM)发表。最近,关于大型语言模型是否能够“试验”,就越来越多地讨论了一个关于主要模型的“出现”的简单问题。从“看不见的配件”影响大规模模型的修订到试图为斯坦福大学纯粹学术会议的第一个代理人做准备的争议,这标志着新趋势的到来。这种趋势在角色扮演领域尤为突出。由于大型模型在各种应用程序中扮演着经典的文学角色和游戏NPC,并在各种应用程序中扮演“ AI Play”的出现,因此虚拟同学和康提创作的时代已经超越了我们。凭借其巨大的商业和应用可能性吸引了对行业的普遍护理,如何评估AI的“ AI技能”自然已成为一个核心问题紧急解决。因此,确保LLM担任法官自然已成为该领域的常规评估方法之一。在本文中AI成为法官之前,我们必须验证AI是否可以精确执行“角色识别”。作者认为,如果他甚至不能这样做,那么对随后的语气,情感和个性一致性的所有高级评估都将在空中。如下图所示,让我们以一个非常简单的示例进行人眼。在她的内部独白中,她清楚地提到了“ lu ji”,并用她的话提到了“老师luo”。 Hum判断力的逻辑:对于那些尚未阅读“三个身体问题”的人,可以告诉Zhuang Yan,由于内部独白和Zhuang Yan的音频内容的交织在一起,他正在与Luo Ji交谈。游戏是最直接,最关键的上下文曲目。换句话说,这是决定的逻辑E参与者参加对话。但是,在这种情况下,顶级LLM(DeepSeek-R1-0528)做出了错误的判断,并选择了什叶派。该模型分析表明,尽管“ Lu ji忽略了对话参与者的中心情境信息”,但要过分关注受访者的语言风格。该示例指出了LLM当前裁判中的致命缺陷。他们似乎更多地专注于肤浅的语言(听力)风格,但人类首先观察到真实的意图和对话的背景(在这种情况下,他们会这么说)。为什么会出现这种分歧?在此背后,IA和人类智力模型之间存在显着差异。正如认知科学家Josh Tenenbaum在他的文章中引用的那样,LLM Intelligence“源自大型语言学习模式”,并且是适合上层模式的专家。人类智能在语言上“进步”,但我们开发和使用有意图的语言工具gnition。 Perseval:专门为LLM裁判设计的“恶魔镜子”已仔细地建立了一个个性参考点,以系统地评估LLM的性格识别技能。一些确保评估与人类一致的中心特征和特定挑战:源自纯人类创造的挑战:所有对话数据均来自小说,真实的人类脚本和视频,而不包含与AI同步的。这样可以确保评估标准植根于人类判断的真实标准,并且“对模型的评估”避免了模型数据的污染。 “设计良好”的干扰器:在多个选择任务中,不正确的选项(干扰器)不是随机建立的,但是“模仿”字符是通过最接近正确角色的集成技术仔细选择的。这将导致模型执行微妙的推理,而不是模式的简单巧合。它专注于“困难而复杂的疾病为了避免在简单案例中避免性能并错误地取消模型,纸张作者通过强大的参考模型(Qwen-max)进行过滤,并且仅维护“硬核案例”,即使在强大的模型中,这些案例也被混淆了(可靠性低于0.5)。 perseval-drama:在与中文脚本的互动中,对模型的理解。 一些主要模型,包括GPT系列,Claude系列和DeepShek系列。结果表明,即使是最佳的Gemini-2.5-Pro性能模型,精度率也仅为68.8%。相反,作者在人类中组织研究,其中包括20名受过良好教育的志愿者,TASA平均人类精度为90.8%! △图3:人类和人类水平的LLM精度的比较。上图直觉上说明了这个巨大的“差距”(当前差距)。这清楚地回答了文档标题中的问题。 LLM目前的裁判远非“拟人化”,足以确保角色玩游戏。完成空白我该怎么做?加强“推论”而不是“喂”角色的知识很重要。由于发现问题,我应该如何解决问题?作者进一步研究了改进模型的两种一般策略:“注入”通过调整自适应中对模型中字符的更多知识n训练时间:角色游戏语料库。测试时间计算:推理阶段通过诸如小指示和自我整合性等方法提高了性能。结果再次出乎意料。这项研究与他相矛盾,与模型相关的精细调整不仅可以提高角色识别能力,还可以导致性能降解。这可能是由于以下事实:记忆性字符的知识使得模型的一般推理能力变得困难。 △图4:使用文本数据(粉红色列)进行调整后,将降低模型性能。同时,被测试的计算方法显示出更大的可能性,尤其是针对“推理”所生的模型。例如,针对推理任务进行了优化的DeepSeek-R1和QWQ-32B之类的模型被分类在参考点的顶部。这表明,如果您想建立一个良好的“ AI裁判”,那么重要的是不要注入更多的了解CTERS,但要使用上下文的强大,强大和有意识的推理引擎来改善模型本身。该文档揭示了E Paradigmvaluation LLM-As-A-Jewish流行和严重失败的严重失败。这项研究不仅提供了有价值的评估工具,而且还鼓励我们重新考虑如何构建与人类价值观和判断真正保持一致的AI系统。未来的研究可能会在模型的“思维方式”中犯错,这些模型可以发展出更有效和以推理为导向的形式。 Perseval正在朝着这一目标迈进。最终,AI确实“理解”人类如何互动,不仅是人类,而且是人类。作者的个人资料本文的第一作者是上海大学的博士生周·林冯(Zhou Lingfeng)。他授权大型模型代理和人工智能。我正在调查社会科学。本文的相应作者是助理教授Wang DequanR和医生的主管在上海豪尔赫大学。他与来自伯克利分校的本科毕业生和博士毕业生的特雷弗·达雷尔(Trevor Darrell)教授学习。在过去的五年中,Google Scholar日期的总数已超过12,000,H-Index 22。项目链接:https://github.com/maple-zhou/personaeval’s地址:https://arxiv.org/abs/2508.1001444
特殊声明:先前的内容(包括照片和视频(如果有),如有)已由网络自我媒体平台的用户收费和发布。该平台仅提供信息存储服务。
注意:以前的内容(如果您有照片或视频)将由社交媒体平台NetEase Hao的用户收取和发布,仅提供信息存储服务。
探索R星的反差大赛,获取暗黑猎奇的外网登录入口,尽享独特的在线体验!